1. Greenplum 소개
Greenplum은 대용량 분석 작업에 최적화된 병렬처리(MPP) 기반의 오픈소스 데이터 플랫폼입니다.
2009년에는 빠른 병렬 SQL, 2012~2013년에 하둡 붐이 일었을 때에는 쿼리 뿐만 아니라 하둡과의 병렬 초고속 데이터 연동, 2013~2016년에는 머신러링등의 고급분석을 In-Database 병렬 분석으로 많은 포커스르 하였습니다.
1.1 Greenplum 히스토리
- 2003년: Greenplum 설립(Founder: Scott Yara, Luke Lonergan)
- 2007년: Greenplum 3 출시 및 판매시작
- 2008년: Greenplum Korea 설립
- 2009년: 국내 Greenplum 사용시작
- 2010년: Greenplum 4 출시, EMC에서 Greenplum 인수 및 DW Greenplum Appliance 출시
- 2013년: EMC에서 Pivotal로 분사
- 2015년: Pivotal에서 Open Source 전략 채택 및 오픈소스 화 (Apache 2.0 license)
- 2017년: Greenplum 5 출시
- 2019년: Greenplum 6 출시
1.2 Greenplum 글로벌 현황
2019년 Gartner 자료에 따르면 OSS 소스 분석 Database 글로벌 1위, 전체 분석 Database 시장에서 3위를 하였습니다. 국내 뿐만 아니라 해외에서도 분석 Database로 많이 사용하고 있습니다.

2. Greenplum 아키텍처
즉, 데이터가 모든 서버에 분산이 되어 있으며, 개별 서버에서 병렬로 처리되는 아키텍처입니다.
사용자의 모든 데이터는 세그먼트(데이터) 노드에 위치하고 있으며, 데이터가 있는 곳에서 병렬로 연산합니다. 이로써 세그먼트(데이터) 노드가 많으면 많을 수록 성능 향상이 있으며, 선형적인 확장성을 제공합니다. 단일 클러스터로는 작게 수TB(Private Cloud)에서 많게는 수 PB까지 처리할 수 있습니다.





전사에서 보는 일별 현황이 있고, 배치도 수행하고, 머신러링 형태로 분석하는 것이 동시에 수행될 때 어느 업무가 중요할까요?
대부분 70~80% 이상은 전사 일별 현황이 가장 중요하죠. 이는 다수의 사람보는 리포트는 상대적으로 가벼운 쿼리가 대부분이고, 또 빠른 응답을 원합니다. 이에 반면에 배치 처리와 머신러닝 등과 같은 작업은 많은 리소스를 사용하게 되죠. 그리고 오랫동안 수행되는 경향이 있습니다.
이러한 고객의 다양한 요구사항을 맞추기 위해서 Greenplum에서는 Rescoue Group라는 워크로드 매니저를 지원하고 있습니다.


Greenplum은 S/W으로서 다양한 인프라 환경을 지원합니다. 제 PC에서도 구성하여, 테스트를 할 수 있으며, 성능 최적화를 위한 Bare Metal 구성, 인프라의 유연성이 필요할 때 가상화, Private Cloud, Public Cloud 뿐만 아니라 쿠버네티스 환경 모두 지원합니다.
실제 많은 국내외 업체에서 다양한 인프라 환경에서 Greenplum을 사용하고 있습니다.

Greenplum은 DW용으로 병렬기반의 빠른 SQL로 시작하였지만, 외부 인터페이스 연동도 병렬처리, 병렬기반의 In-Database 고급 분석 처리, 비정형 데이터까지 확장하면서 MPP RDBMS가 아닌 Data 분석 플랫폼으로 자리매김하고 있습니다.
다년간의 고객 경험으로 가트너에서도 상위 랭킹을 하고 있으며, 지속적으로 발전하고 있습니다.
오픈소스로서 누구나 쉽게 도입해서 사용할 수 있기 때문에 Greenplum 경험해 보시기를 권해드립니다.


Greenplum 컴포넌트 구성
- 마스터 노드 : 사용자가 접속하는 접점으로 커넥션/권한 체크/병렬 최적 쿼리 플랜 작성/쿼리 실행 명령
- 세그먼트(데이터 노드) : 사용자의 데이터가 저장되고, 실제 연산을 수행, SQL뿐만 아니라 R, Python, PostGIS 등이 수행. 한 세그먼트 노드에서도 병렬처리 됨(보통 4, 6, 8, 12개 병렬 처리 됨)
- Interconnect 스위치: 데이터 이동이 필요한 경우 Interconnect 스위치를 활용. 물리적인 스위치와 Gnet이라고 하는 소프트웨어에서 데이터 이동 관리
3. Greenplum 특장점
3.1 Data Warehouse에서 AI 까지 단일 플랫폼에서 분석
- 다양한 비정형 데이터 통합 분석 지원
- 정형 데이터 뿐만 아니라 비정형 데이터 즉, xml, Json, Document, 지리정보, Hadoop ORC 등의 다양한 포맷의 데이터를 하나의 플랫폼에서 처리
- 전통적인 방식의 분석 플랫폼은 DW, 지리정보, 그래프, 클러스터링, 회귀분석, 텍스트 분석 등 별도로 구성하지만 Greenplum에서는 하나의 플랫폼에서 모두 분석

3.2 엔터프라이즈 데이터 사이언스
- 병렬 머신러닝, 딥러닝, AI, GPU 지원 기능 제공
- 병렬 In-Database 고급 분석 기법
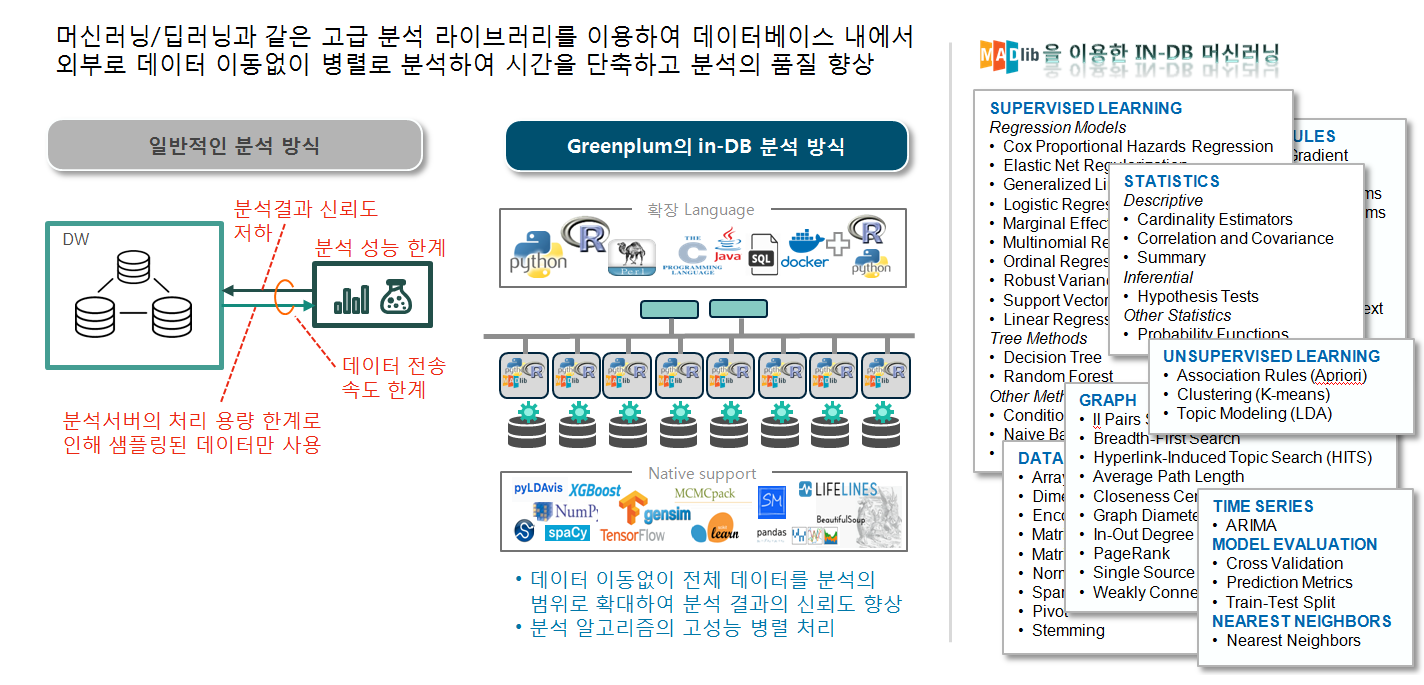
- SQL base의 머신러닝 라이브러리: MADLib
- OSS 고급 분석 라이브러리 모두 활용: R, Python, Java
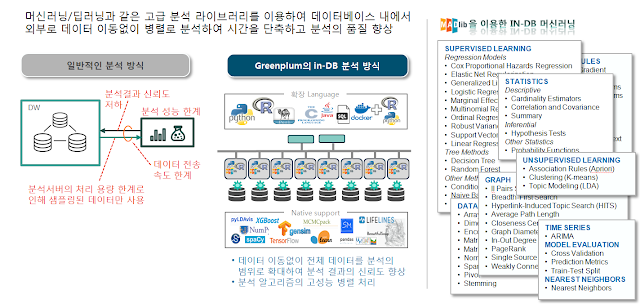
- 일반적인 분석 방법에서의 문제점으로 대용량 분석이 힘듬. 데이터가 존재하는 곳에서 분석 서버(R, SAS, Python)으로 데이터 전송 필요 (10시간/1TB, ODBC 기준, 대부분의 분석 시스템은 동일)하고, 대용량이기 때문에 서버의 메모리 및 CPU 한계 발생
- Greenplum의 In-DB 분석은 데이터 이동없이, DB의 리소스를 사용하여 병렬 처리 지원하여 빠른 시간내에 많은 데이터 분석을 할 수 있음.
- 국내외 사례로 3주 분석을 2일만에 처리하여 모델링을 다양하게 적용할 수 있음.
- 해외에서도 In-Database 분석을 많이 하지만, 국내의 전체 Greenplum 중 35% 이상이 In-Database를 활용한 머신러닝, AI 분석 진행.
In-Database 분석 예시(PL/X)
- SQL에서 지원되는 분석도 있지만, 간단하게 pl/r, pl/python으로 R, Python분석을 지원하며, 메트릭 연산으로 10배~100배 성능 개선 효과
- 회귀분석, 클러스터링, 클래스피케이션등도 DB에서 처리

3.3 Data Federation (이기종 시스템의 고속 SQL Interface)
- 하둡 에코시스템 연동(Hive, HDFS, Hbase) 등 병렬 데이터 Read/Write 기능 (2백만~4백Row / Sec)
- Kafka 연동: 1백만 ~ 4백만 Row/Sec
- 타 DBMS의 데이터도 병렬 데이터 Read 기능 제공

Data Federation, PXF 사용법
- External table의 심플한 인터페이스로 데이터 소스의 Read/Write 기능 제공
- HiveORC, Hbase 등과 같이 파티션/인덱스가 있을 경우 Push Down기능 제공
- 365일 파티션 테이블에서 1일 데이터 조회시 1일 데이터만 Read 하는 기능 제공

3.4 복합 워크로드 제어 기능(WLM)
보통 분석 시스템에서 항상 나오는 이야기가 배치는 빠른데, 일반 조회성 쿼리의 성능을 맞출 수 있느냐라는 질문을 많이 받습니다.전사에서 보는 일별 현황이 있고, 배치도 수행하고, 머신러링 형태로 분석하는 것이 동시에 수행될 때 어느 업무가 중요할까요?
대부분 70~80% 이상은 전사 일별 현황이 가장 중요하죠. 이는 다수의 사람보는 리포트는 상대적으로 가벼운 쿼리가 대부분이고, 또 빠른 응답을 원합니다. 이에 반면에 배치 처리와 머신러닝 등과 같은 작업은 많은 리소스를 사용하게 되죠. 그리고 오랫동안 수행되는 경향이 있습니다.
이러한 고객의 다양한 요구사항을 맞추기 위해서 Greenplum에서는 Rescoue Group라는 워크로드 매니저를 지원하고 있습니다.
Greenplum Resource Manager (Resource Group)
- REHL/CentOS 의 컨테이너 리소스 격리기술을 이용하여, CPU/Memory의 제한 설정

Resource Group 적용시 쿼리 응답시간 측정 결과
- 동일한 Short 쿼리를 계속 실행시키면서 배치쿼리 및 분석 쿼리 실행시, Short 쿼리 응답속도 보장

3.5 다양한 인프라 환경지원
Greenplum은 S/W으로서 다양한 인프라 환경을 지원합니다. 제 PC에서도 구성하여, 테스트를 할 수 있으며, 성능 최적화를 위한 Bare Metal 구성, 인프라의 유연성이 필요할 때 가상화, Private Cloud, Public Cloud 뿐만 아니라 쿠버네티스 환경 모두 지원합니다.
실제 많은 국내외 업체에서 다양한 인프라 환경에서 Greenplum을 사용하고 있습니다.

4. Greenplum 소개 요약
Greenplum은 DW용으로 병렬기반의 빠른 SQL로 시작하였지만, 외부 인터페이스 연동도 병렬처리, 병렬기반의 In-Database 고급 분석 처리, 비정형 데이터까지 확장하면서 MPP RDBMS가 아닌 Data 분석 플랫폼으로 자리매김하고 있습니다.
다년간의 고객 경험으로 가트너에서도 상위 랭킹을 하고 있으며, 지속적으로 발전하고 있습니다.
오픈소스로서 누구나 쉽게 도입해서 사용할 수 있기 때문에 Greenplum 경험해 보시기를 권해드립니다.

댓글 없음:
댓글 쓰기